爬虫进阶-ip代理(Proxy)¶
缘由
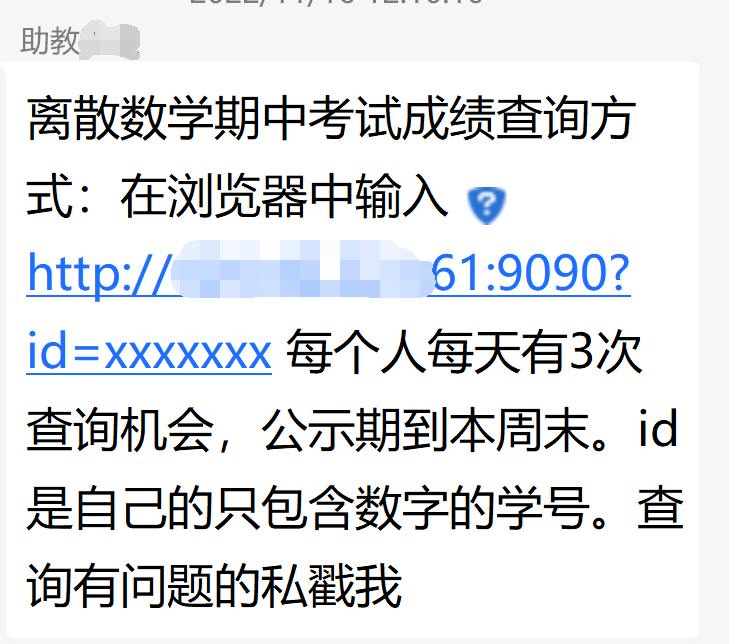
又到了考试出分的阶段, 这次助教玩了点花样: 通过向服务器发送一个请求, 将成绩直接打印在页面上. 不过通过记录访问的IP地址, 对每个ip每天查询分数的次数进行限制.
那么, 有没有办法, 冲破这个限制呢? 答案就是鼎鼎大名的"ip代理".
ip代理其实是很寻常的东西, 平时的"梯子", 也是通过ip代理的方式, 通过境外的ip进行访问, 再通过代理的方式间接上网.
ip代理的更强大的使用场景就是爬虫了, 通过proxy的方式, 可以实现高匿名的访问, 也可以轻松冲破网站的ip封锁.
本文就记录一下实操过程, 这样以后再使用的话可以有所参考.
使用方式: 在requests请求时附加proxies=参数, 将得到的proxies放入即可.
可以访问一些特定的网站(如http://icanhazip.com/)来判断当前ip代理是否成功.
proxy格式:
proxy = {
'http': ip:port
'https': ip:port
}
ip获取
其实很简单, 获得门牌号(ip地址)+身份/钥匙(authKey/authSecret)
鉴于国内的ip池的价格十分低廉(甚至注册就送, 代价是个人隐私信息的泄露), 有的网站(如https://www.juliangip.com/)甚至每天免费提供1000个ip. 对于强度不大的ip代理爬虫已经足够.
具体的如何获得ip的方式大致是利用网站提供的接口. 这个就RTFM了.
实例代码
import time
import re
import requests
from requests.auth import HTTPProxyAuth
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.193 Safari/537.36'
}
url = 'http://101.42.221.61:9090?id=' # 最终请求的网站URL
ip = '' # 通过ip池提取的ip
proxies = {
'http': ip,
'https': ip
}
auth = HTTPProxyAuth("USERNAME", "USERPWD") # ip验证的账号和密码
# 向ip代理网站请求提取ip
def getIP():
getIPUrl = "http://v2.api.juliangip.com/dynamic/getips?area=%E6%B1%9F%E8%8B%8F,%E5%8D%97%E4%BA%AC&filter=1&isp=%E7%94%B5%E4%BF%A1&num=1&pt=1&result_type=text&split=1&trade_no=1152845013074502&sign=e30c961c58d3541005b58f5d70967497"
newIp = requests.get(url=getIPUrl, auth=auth).text
print("newIP: " + newIp)
return newIp
# 更新Proxy
def updateProxy():
newIP = getIP()
proxies['http'] = newIP
proxies['https'] = newIP
nameList = [211830066,
211850009,
215220019,
215220010,
215220008,
215220005,
215220002,
211870171,
211840154,
211840112,
211503026,
211200015,
211180111,
211098324,
205220026,
201830099,
201810069,
191870226,
191870072,
191830074,
191220048,
191180008,
211870298,
215220008,
215220002,
211870202,
211870180,
211840245,
211820282,
211220167,
211108100,
205220011,
201840100,
191180123
]
ansList = {}
for name in nameList:
updateProxy()
curUrl = url + str(name)
print(curUrl)
# print(proxies['http'])
res = requests.get(headers=headers, url=curUrl, proxies=proxies, verify=False).text
curIPis = requests.get(url="http://icanhazip.com/", proxies=proxies).text # 验证当前代理的ip是否成功.
print(curIPis)
print(res)
pts = re.findall(r"[0-9]+", res)
if len(pts) != 0 and pts[0] != 58:
ansList[name] = pts[0]
print(str(name) + " " + str(pts[0]))
time.sleep(1)
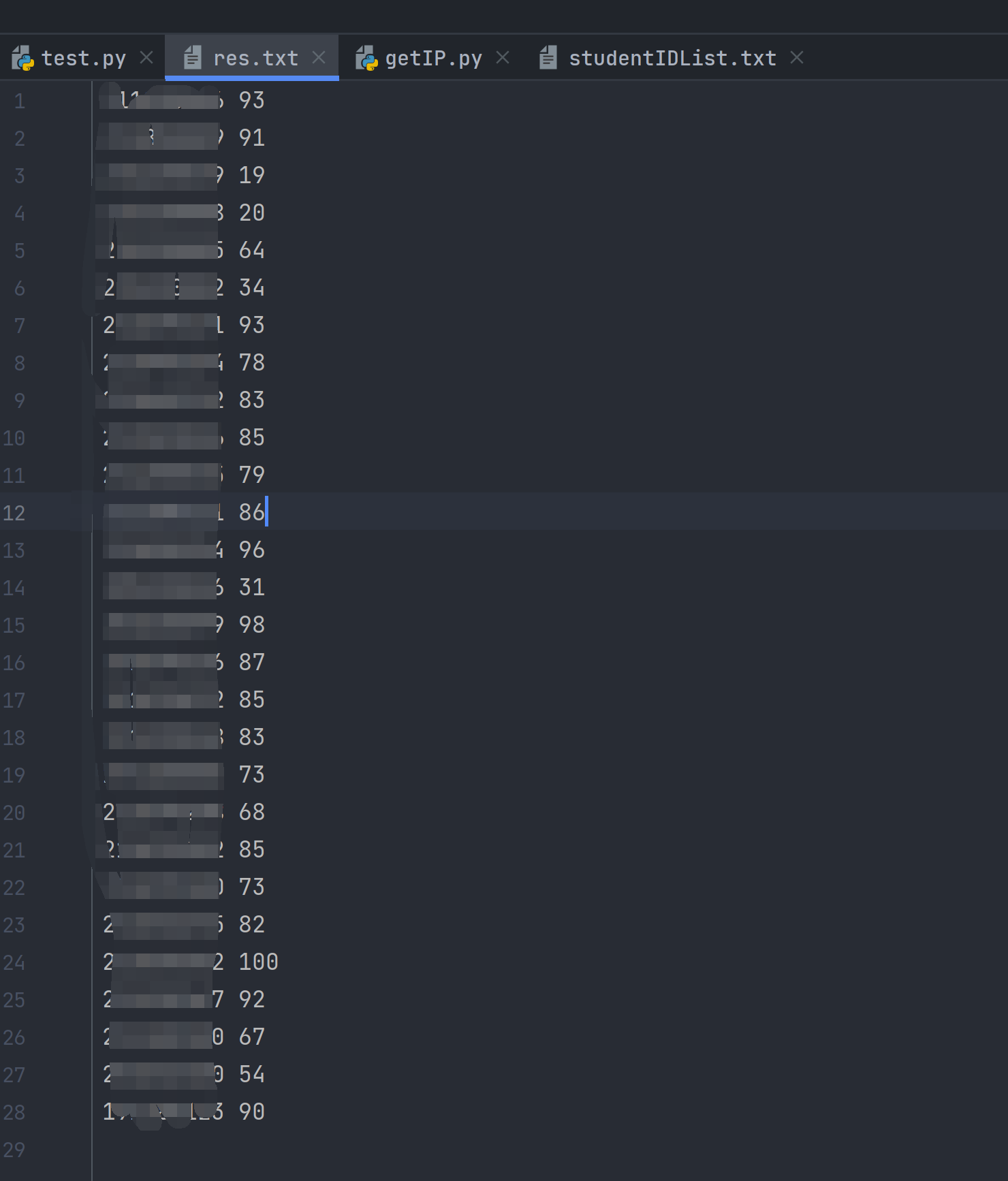
with open("./res.txt", 'w', encoding='utf-8') as fp:
for x in ansList:
string = str(x) + " " + str(ansList[x])
fp.write(string + '\n')
print('finished!')